
用于高频交易中实时中间价预测的自适应学习策略AI引擎
高频交易(HET)改变了现代金融市场,使可靠的短期价格预测模型变得必不可少。在本文我们提出了一种新的方法来预测中间价格,使用来自纳斯达克的一级限价订单(LOB)数据。重点关注2022年9月至11月期间标准普尔500指数中的100只美国股票。在我们之前的径向基函数神经网络(RBFNN)工作的基础上,我们引入了自适应学习策略引擎(ALPE)——一种基于强化学习(RL)的智能体,设计用于无批量、即时的中
“Minimal Batch Adaptive Learning Policy Engine for Real-Time Mid-Price Forecasting in High-Frequency Trading”
高频交易(HFT)在现代金融市场中至关重要,短期价格预测面临高速度和复杂性挑战,传统统计模型效果有限。本文引入了一种新的强化学习(RL)框架,能够根据市场变化动态调整预测策略,提供更灵活的解决方案。
在对100只标准普尔500指数股票的NASDAQ Level 1 LOB数据进行严格实证评估时,ALPE在扩展的GD数据集上实现了RRMSE为2.484E-04,较GRU(1.178E-03)和MLP(9.202E-04)分别降低约79%和73%。RRMSE指标显示ALPE在不同交易量下的有效性,绝大多数股票的误差显著改善,证明该指标在股票比较中的价值。

论文地址:https://arxiv.org/pdf/2412.19372
摘要
高频交易(HET)改变了现代金融市场,使可靠的短期价格预测模型变得必不可少。在本文我们提出了一种新的方法来预测中间价格,使用来自纳斯达克的一级限价订单(LOB)数据。重点关注2022年9月至11月期间标准普尔500指数中的100只美国股票。
在我们之前的径向基函数神经网络(RBFNN)工作的基础上,我们引入了自适应学习策略引擎(ALPE)——一种基于强化学习(RL)的智能体,设计用于无批量、即时的中间价格预测。RBFNN利用了基于平均减少杂化(DI)和梯度下降(GD)的自动化特征重要性技术。ALPE采用自适应epsilon衰减来动态平衡勘探和开发,在预测性能方面优于各种高效的机器学习(L)和深度学习(DL)模型。
简介
高频交易(HFT)在现代金融市场中至关重要,短期价格预测面临高速度和复杂性挑战,传统统计模型效果有限。之前的研究中,提出了一种基于径向基函数神经网络(RBFNN)的模型,利用自动特征选择技术提升中间价格预测准确性,表现优于传统方法。
本文引入了一种新的强化学习(RL)框架,能够根据市场变化动态调整预测策略,提供更灵活的解决方案。进行了一系列模型比较,包括ARIMA、MLP、CNN、LSTM、GRU和RBFNN,评估RL模型在不同输入数据和特征重要性技术下的表现。研究的主要贡献在于扩展基准模型和股票数量,探讨RL在HFT LOB数据中的预测潜力,显示其在捕捉非线性依赖方面的优势。
方法
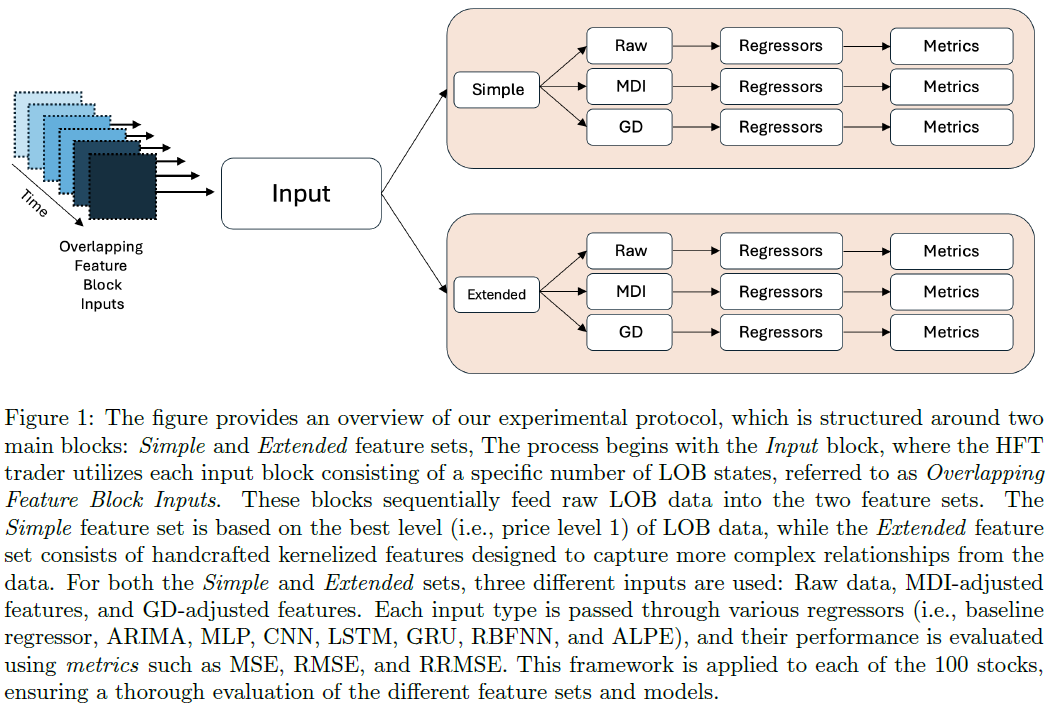
本文介绍了ALPE模型的实验方法,包括数据集、预处理技术、RL环境和ALPE代理架构。
与RBFNN、ARIMA、CNN、LSTM、GRU等模型进行比较,包含简单基线回归模型。
使用三种输入特征集:MDI特征重要性、GD和原始LOB数据,确保评估公平性。
主要评估指标为均方误差(MSE)、均方根误差(RMSE)和相对均方根误差(RRMSE)。
预测目标
本研究旨在预测限价订单簿(LOB)的中间价格,作为交易活动的代理。准确估计中间价格的变动有助于理解大订单的价格影响。采用事件回归模型DQR,目标是最小化预测误差,评估指标包括MSE、RMSE和新提出的RRMSE。与多种基准模型(如ARIMA、LSTM、GRU等)进行性能比较。
中间价格定义为最佳买入价和卖出价的平均值。
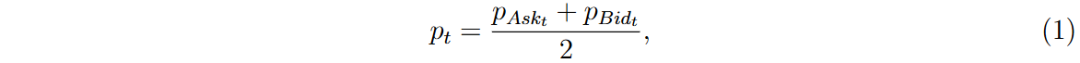
RRMSE定义为相对均方根误差,基于时间事件t的RMSE计算。实验采用事件为基础的协议,无采样技术。
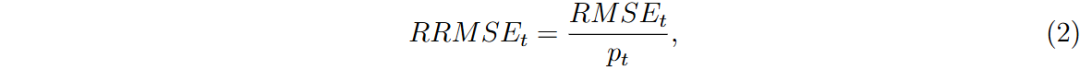
本文采用事件驱动的在线预测目标,包含批量训练和无批量学习设置。竞争模型包括基线回归、ARIMA、MLP、CNN、LSTM、GRU和RBFNN,均为批量训练;新开发的ALPE模型为无批量设置。
为确保公平比较,采用滚动窗口实验协议,基于10个LOB状态进行训练,因观察到每10个交易事件间存在平稳与非平稳时间序列的交替。竞争模型在减少训练LOB状态数量时性能显著下降。ALPE模型遵循相同的滚动窗口协议,但窗口大小为1,仅使用当前LOB信息。
数据预处理与特征工程
HFT中,数据预处理和特征工程对模型性能至关重要,因数据噪声大且维度高。有效的预处理确保特征适当缩放,增强学习算法的稳定性和收敛性。描述了采用的预处理步骤,包括通过MDI和GD方法计算特征重要性,以及基于最小-最大缩放的数据归一化。
MDI(Mean Decrease Impurity)
MDI(Mean Decrease Impurity)是基于随机森林(RF)的特征重要性方法,通过计算特征在所有树中减少的不纯度平均值来评估特征重要性。在回归任务中,使用方差作为不纯度指标,节点j的方差不纯度计算公式为:
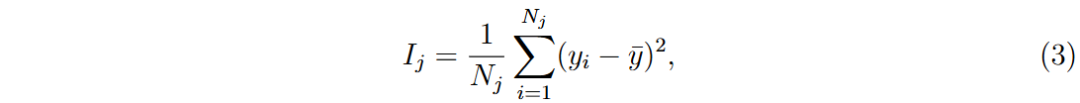
训练过程中,算法通过节点分裂来最小化不纯度,特征f在节点j的 impurity reduction(不纯度减少)为:
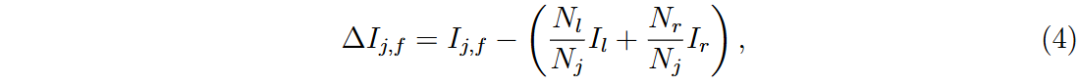
MDI特征f的计算公式为:
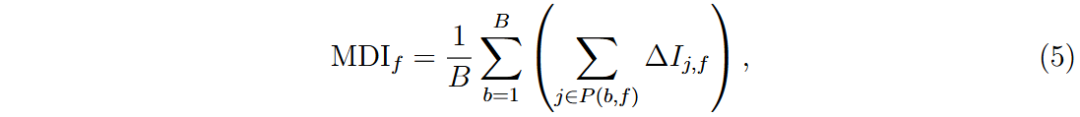
为在树b中以特征f进行分裂的节点集合。
GD(Gradient Descent)
GD算法是一种一阶优化技术,通过迭代更新参数来最小化损失函数,优化特征权重以降低均方误差(MSE)。
初始化输入矩阵X(样本数N和特征数F)和目标变量y(LOB中间价格),权重向量θ初始为全1。
预测值计算每个样本的预测值。
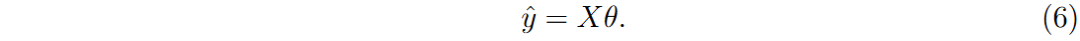
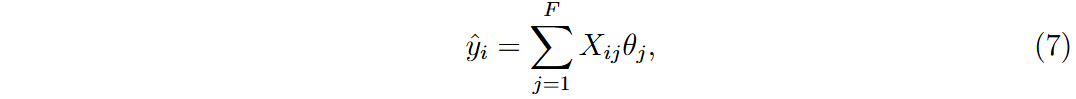
误差项用于比较预测值与真实值。
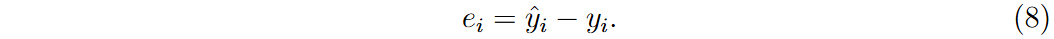
目标函数J(θ)定义为所有样本的MSE,计算每个权重的梯度以更新特征权重。为确保数值稳定性,处理梯度中的NaN或无穷值,并应用梯度裁剪。
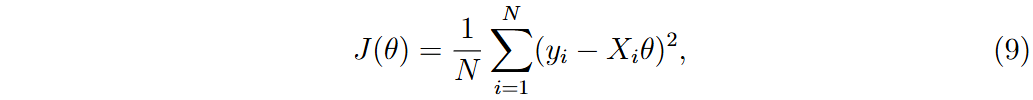
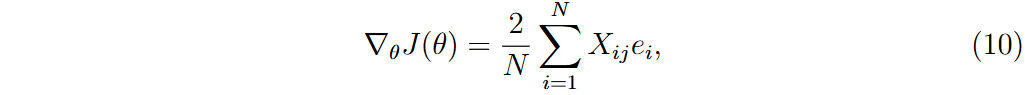
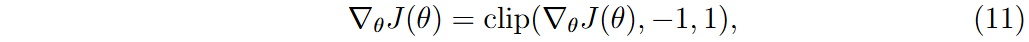
权重更新公式为
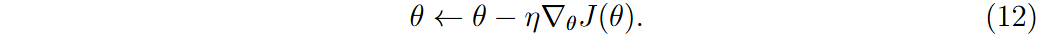
算法
特征重要性(FI)向量通过MDI和GD方法的权重绝对值表示,FI MDI和FI GD分别为两种算法的特征重要性向量。
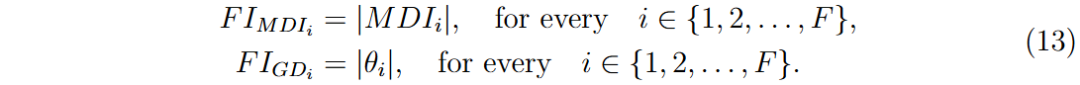
为确保数值稳定性,最终特征重要性分数中添加了小常数δ(0.001)。
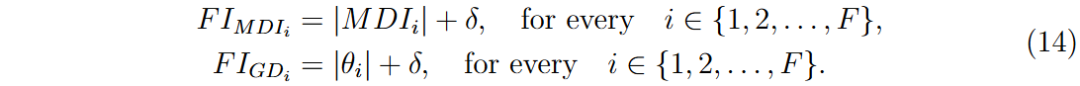
特征矩阵的变换公式为:
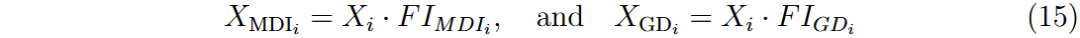
固定迭代次数为10,通常在7次时已达到收敛。
算法流程在算法1和算法2中进行了概述。

特征工程
使用来自一级订单簿(LOB)的多样特征预测中间价格变动,特征分为简单组和扩展组。

简单组包含四个关键特征:最佳买入价(P1 bid)、最佳卖出价(P1 ask)及其对应的交易量(V1 bid、V1 ask),反映市场流动性和供需平衡。扩展组通过变换最佳买入卖出价提供更深入的见解,包括中间价格(u2)、买卖差价(u3)和周期性成分的正弦变换(u4)。
合成特征(u5至u8)捕捉价格与交易量的非线性交互,u5和u6为最佳买入卖出价与交易量的乘积,u7和u8引入二阶依赖性。扩展组还包括多种核变换:线性核(u9)、三次多项式核(u10)、Sigmoid核(u11)、指数核(u12)和RBF核(u13),用于捕捉复杂的非线性关系和局部模式。
强化学习-深度策略价值学习
ALPE RL框架使用深度学习模型近似最优动作价值函数,以预测高频交易中的中间价格。该方法为无模型、基于价值的强化学习,代理通过与环境的直接互动学习。
环境包括当前的限价订单簿(LOB)状态、动作边界、LOB特征集(简单和扩展)以及惩罚偏离实际中间价格变动的奖励函数。代理以事件驱动的在线学习方式运作,基于新进的LOB数据不断适应。文中将详细介绍代理的不同组件,包括环境、动作和奖励结构、内部深度学习模型架构及学习过程。
马尔可夫决策过程表示
该问题建模为马尔可夫决策过程(MDP),由状态集S、动作集A、奖励R和折扣因子γ组成。
状态s_t为时间t的LOB特征向量,包括买价、卖价等市场指标。
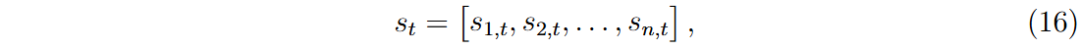
动作集A表示对中间价预测的调整,采用ε-贪婪策略选择动作,探索参数ϵ随时间衰减。
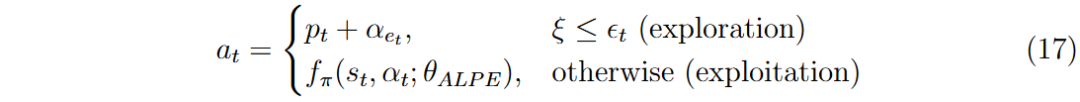
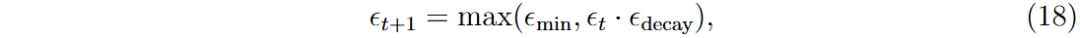
环境转移为马尔可夫过程,下一状态s_{t+1}仅依赖于当前状态s_t和动作α_t,转移是确定性的。
奖励函数R(s_t, a_t)基于预测中间价与真实中间价的偏差,鼓励减少预测误差。
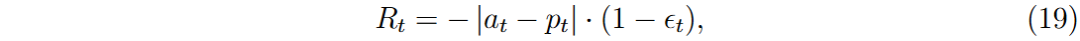
折扣因子γ设为0,专注于最大化即时奖励,适应高频交易的快速变化。
网络架构
使用多层感知器(MLP)作为非线性回归器,近似策略价值函数 f π (s t , a t ; θ ALPE),表示在当前策略下,状态 s t 采取动作 a t 的即时奖励调整。
网络结构:
-
输入层:接收当前状态 s t ∈ R n。
-
隐藏层:8层,每层64个神经元,使用ReLU激活函数。
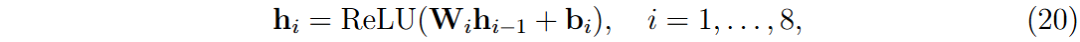
- 批量归一化:在第一隐藏层后应用,以稳定学习和提高收敛性。
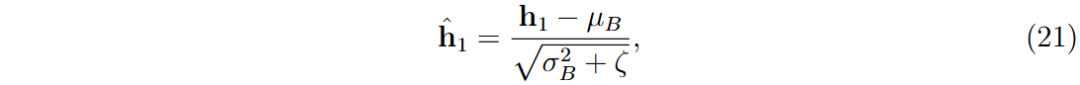
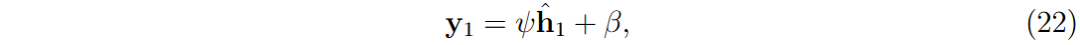
- 输出层:第九层,单个神经元,预测策略价值
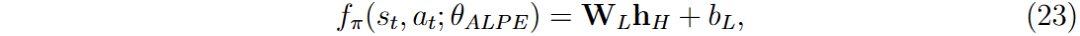
- 归一化和缩放:使用可学习参数对归一化输出进行缩放和偏移。
最小训练下的策略值逼近
政策价值函数 f π (s t , a t ; θ ALPE) 近似在当前策略下采取行动 a t 在状态 s t 的期望累积奖励。每一步计算的政策价值目标 f π ,target (s t , a t ; θ ALPE) 反映了调整后的期望奖励。
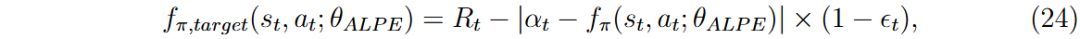
政策价值目标的定义涉及当前奖励 R t 和探索惩罚。
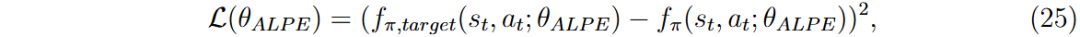
网络目标是最小化预测政策价值与目标政策价值之间的平方差。训练过程使用自适应动量估计(Adam)优化器,仅需两个周期,因输入信息有限,模型快速收敛
模型架构的新颖性
-
**在线适应:**代理在事件驱动下持续调整策略,实时更新策略价值网络。
-
**奖励平衡机制:**奖励函数设计为惩罚预测误差,同时考虑探索因子,平衡探索新行动与利用既有策略。
-
**马尔可夫结构:**框架基于马尔可夫假设,当前LOB状态为RL代理决策提供相关信息。
结果
本研究使用了来自NASDAQ的Level 1 LOB HFT数据集,时间范围为2022年9月1日至11月30日,涵盖100只股票。
为了评估ALPE模型的表现,比较了多种预测模型,包括ARIMA、Naive回归、MLP、CNN、LSTM、GRU和RBFNN。每个模型运行十次以计算平均RMSE和RRMSE,减少随机波动对性能指标的影响。ALPE模型在三个月的测试期间内,预测中价变动时的误差最低。
Amazon股票的ALPE模型在Exte数据集上表现最佳,RMSE和RRMSE均最低。在Simple数据集上,ALPE的RMSE为5.586E-02,RRMSE为4.906E-04;在Exte数据集上,RMSE为2.527E-02,RRMSE为2.732E-04。
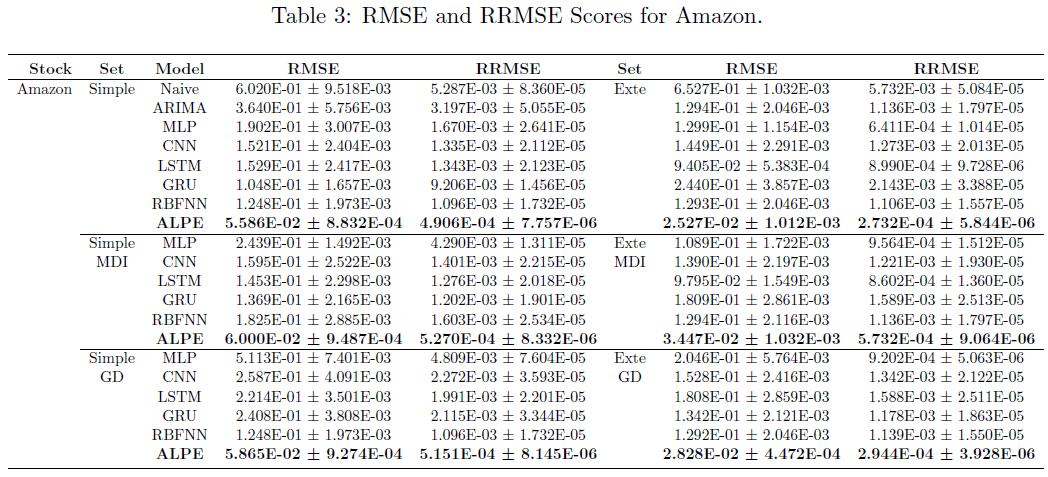
ALPE模型在所有简单和复杂数据集上均优于竞争模型,显示出其在噪声信号下的有效性。对于不同股票,噪声信号的有用性可能不同,例如WBD的特征工程影响了ALPE模型的表现,但仍优于竞争模型。
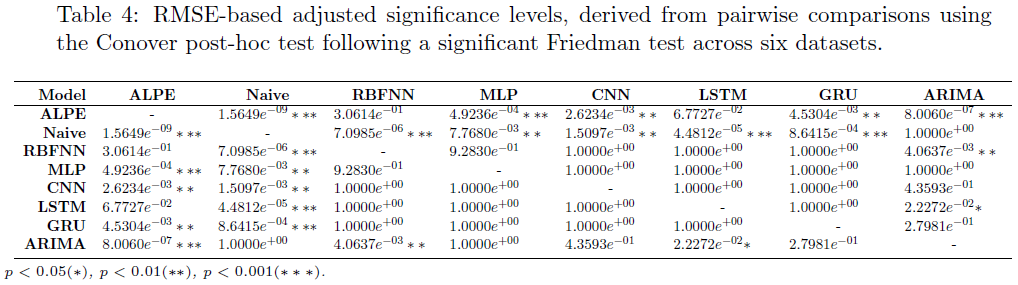
ALPE模型在大多数股票中通过使用非线性输入空间(Exte GD)显著降低了RRMSE值,提升了性能。经过Friedman检验后,Conover后续检验显示ALPE在多种数据集上显著优于其他机器学习和深度学习模型,尤其在处理噪声HFT数据时。
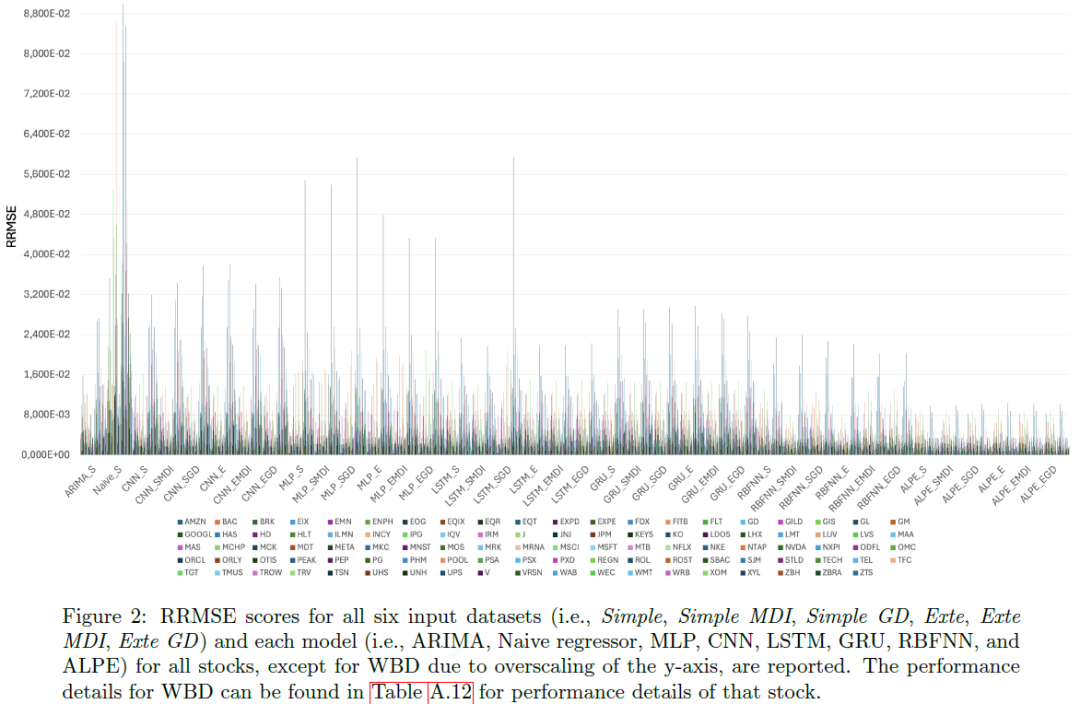
ALPE相较于Naive和ARIMA模型的RMSE改进具有高度显著性(p<0.001),对CNN和MLP也表现出统计显著优势(p<0.01)。对于低交易量股票,RRMSE比RMSE更能准确反映预测误差,建议HFT交易者优先使用RRMSE评估表现。
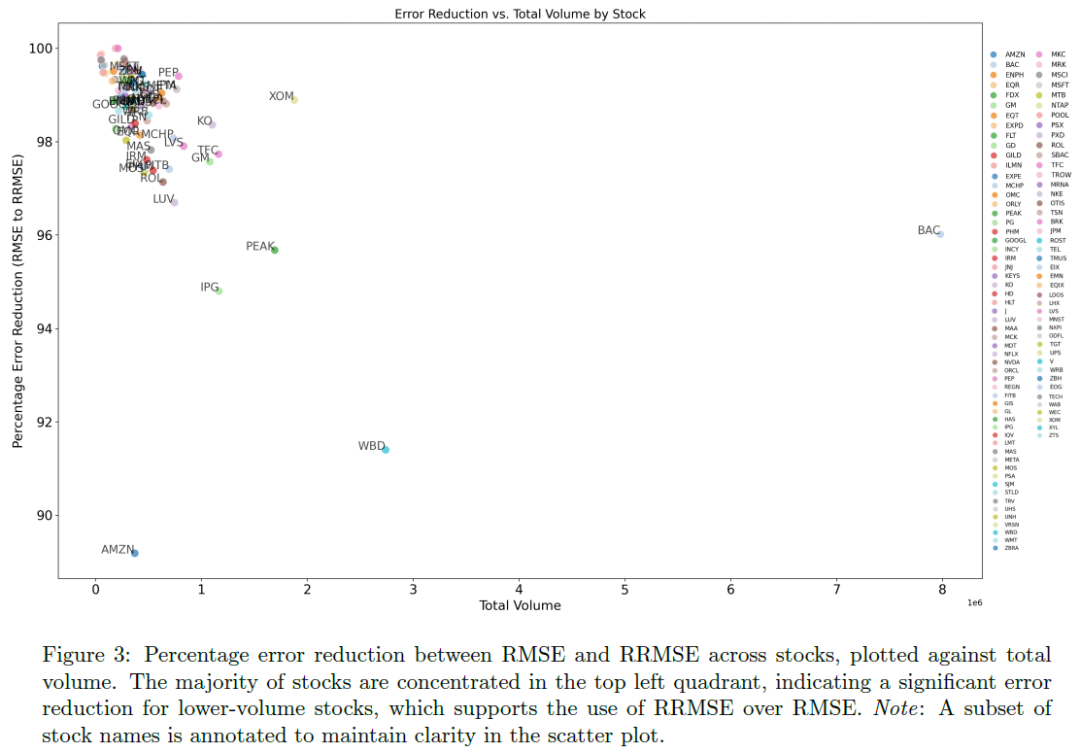
ALPE在不同交易量股票的表现分析显示,复杂特征集对高流动性市场(如BAC和XOM)至关重要,而简单输入配置(如WBD和IPG)适用于低交易量股票,有助于降低计算成本。
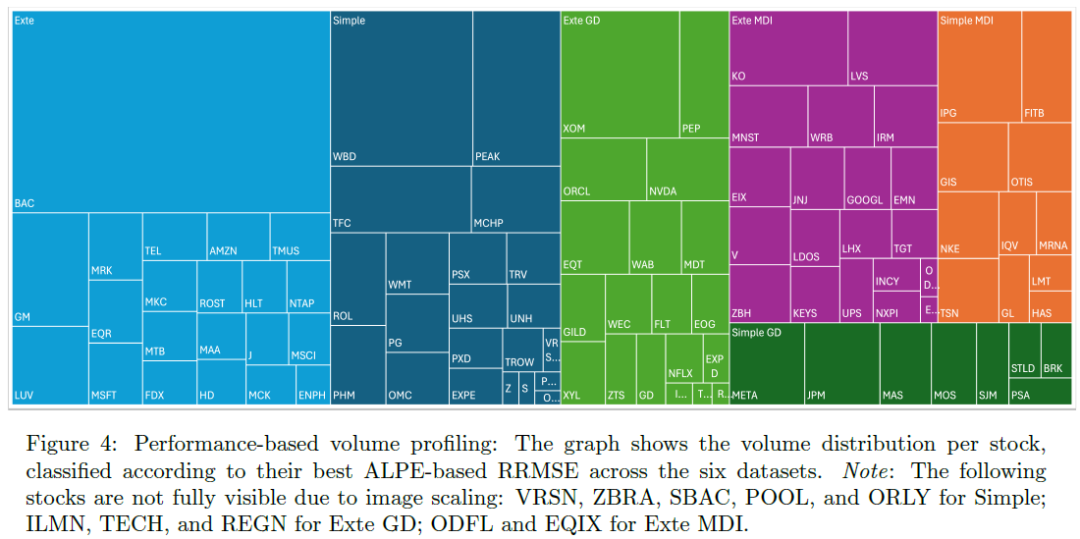
总结
本研究提出了一种新型的基于最小批次强化学习的模型ALPE,专注于高频交易中的中价预测,仅依赖当前的限价订单簿(LOB)状态。ALPE通过自适应epsilon衰减和精细调节的奖励结构,动态平衡探索与利用,显著降低了预测误差。
在对100只标准普尔500指数股票的NASDAQ Level 1 LOB数据进行严格实证评估时,ALPE consistently outperforming多种基准模型。以亚马逊股票为例,ALPE在扩展的GD数据集上实现了RRMSE为2.484E-04,较GRU(1.178E-03)和MLP(9.202E-04)分别降低约79%和73%。RRMSE指标显示ALPE在不同交易量下的有效性,绝大多数股票的误差显著改善,证明该指标在股票比较中的价值。
未来研究可探讨将ALPE模型整合进多智能体强化学习框架,提升其在合作与竞争场景中的能力。适应处理Level 2 LOB数据可能使ALPE捕捉更广泛的市场动态,为实时高频交易预测提供可靠框架。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
更多推荐
 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)